
The emerging field of Embeddings UX
Sparse autoencoders, a meetup in NYC and the future of Latent Scope

I’m very excited to share that Latent Scope has been accepted as a member of the Mozilla Builders Accelerator! It's a 12 week program to accelerate the development of open source AI projects focused on local AI. It's been incredibly energizing to meet the other 13 projects in the program and the Mozilla team that's supporting us. My goal for the program is to get Latent Scope to a solid 1.0 version. I've begun detailing what that means in the github milestones but the TLDR is improved UX, improved developer experience, and a new way of filtering data using Sparse Autoencoders!
This is an exciting time for embeddings, perhaps you know them as hidden states, neuron activations or latent vectors. Whatever you call them, they are starting to get their moment in the sun. The idea that we can create new user experiences by directly working with hidden states isn't exactly new, but it is taking off with researchers and startups in some exciting ways. I've got some new research developments to share in this space, but first I want to introduce an event we're putting together tomorrow in New York:
Embeddings UX NYC
Wednesday, Sept. 25th at Nomic HQ w/ Modal Labs & Latent Interfaces

We're pulling together a panel discussion on the latest in user interfaces for embeddings with 5 people doing state of the art research and prototyping in the field. I'll briefly introduce the panel with links to their work, as that alone is a good overview of where things are going:
Leland McInnes is a researcher at the Tutte Institute and well known for his work on UMAP, HDBSCAN and DataMapPlot. I'm also excited to see his nascent EVoC project optimized for clustering embeddings.
Linus Lee is a researcher and prototyper who just moved from Notion to Thrive Capital. His work on Prism has inspired me (and many others) to dig deeper on Sparse Autoencoders for better UX with embeddings.
Adam Pearce is a veteran ML visualization developer, formerly at Google Research and now at Anthropic. Adam's contributions to Scaling Monosemanticity (i.e. the Golden Gate Claude paper) introduced state of the art visualizations of Sparse Autoencoders on LLMs.
Yondon Fu is a co-founder of Livepeer and has been doing very interesting prototypes of new user interfaces like Feature Packs. These prototypes focus on image models, demonstrating visually just how compelling Sparse autoencoders for embedding based UX can be.
Andriy Mulyar is a co-founder of Nomic, building not just a new kind of UX via Nomic Atlas but also training SOTA embedding models and releasing open source libraries like deepscatter.
As you can imagine, I'm incredibly excited to hear from these folks and I have the privilege of moderating the discussion. While the event won't be recorded, I will be writing a follow-up with my learnings from the event. I also want to do more of these, in San Francisco as well as online, so let me know if you'd be interested in the next one!
New research: Sparse Autoencoders
You might have noticed a theme on the panel: 3 of the 5 have done work with Sparse autoencoders. SAEs are a powerful technique for examining the inner layers of LLMs. Recently, I trained my own Sparse autoencoder on the nomic-text-embed-v1.5 sentence embedding model.
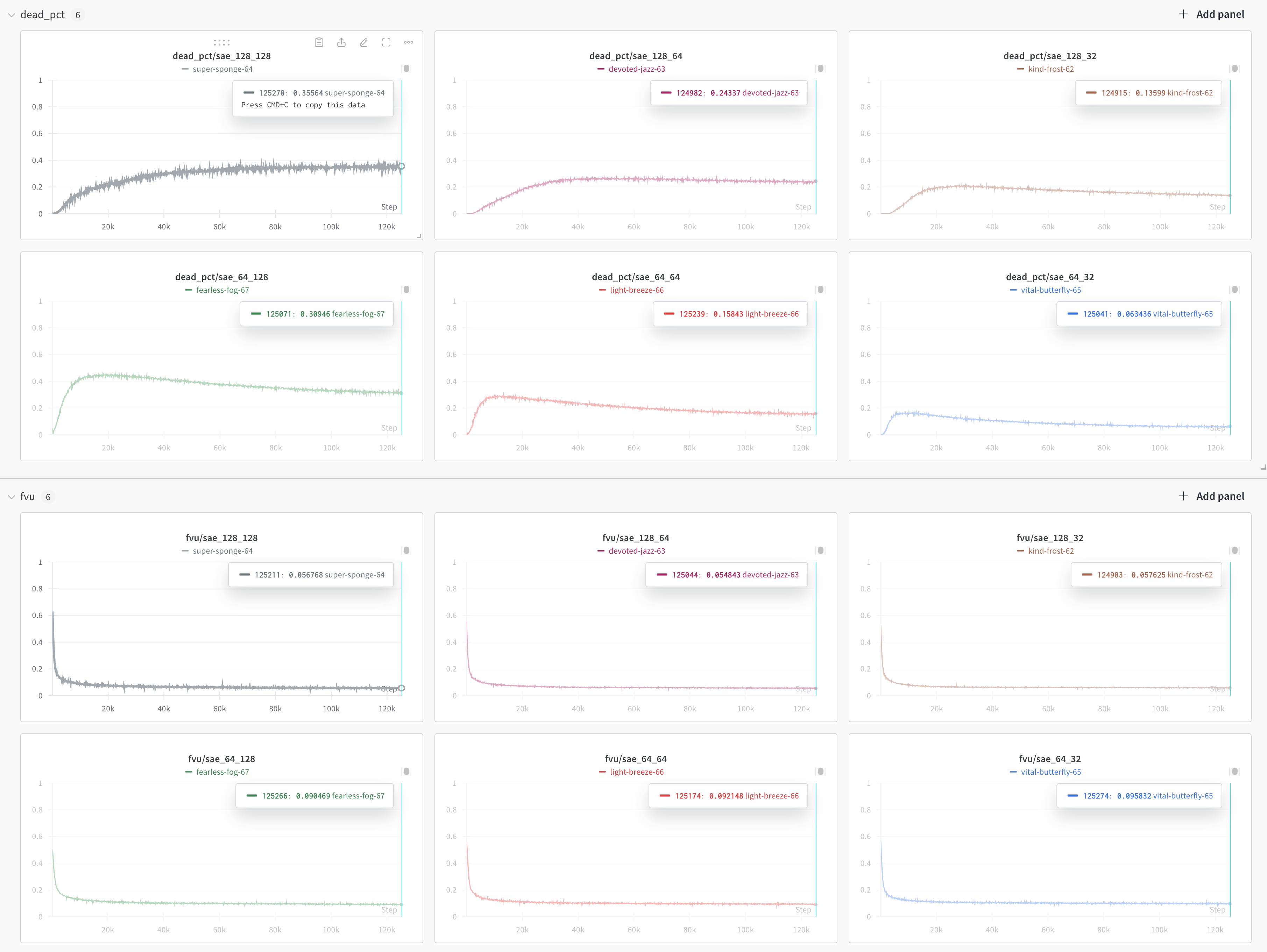
The experience was illuminating, as it was the first model I've actually trained from scratch, and I've done my best to write-up what I did and what I learned in this detailed article.
Why Sparse Autoencoders? They allow us to try and tease out unique directions in the latent space of a model in an automated way. You may have heard of style vectors (this distill article on augmenting human intelligence is my favorite articulation of the idea) but that usually involves a lot of manual work finding each vector. SAEs let us find thousands or millions of directions at once. Then of course the trick is interpreting (i.e. labeling) those directions, where the current best practice seems to be asking an LLM to summarize data samples that highly activate for each direction. Once you've produced and labeled the SAE features for a given model, you can then use them as a lens to look at your data.
I'm working towards integrating this technique into latent scope in several steps:
Training SAEs on popular embedding models, I've already started with nomic-text-embed-v1.5. This work is being done in the latent-sae repo.
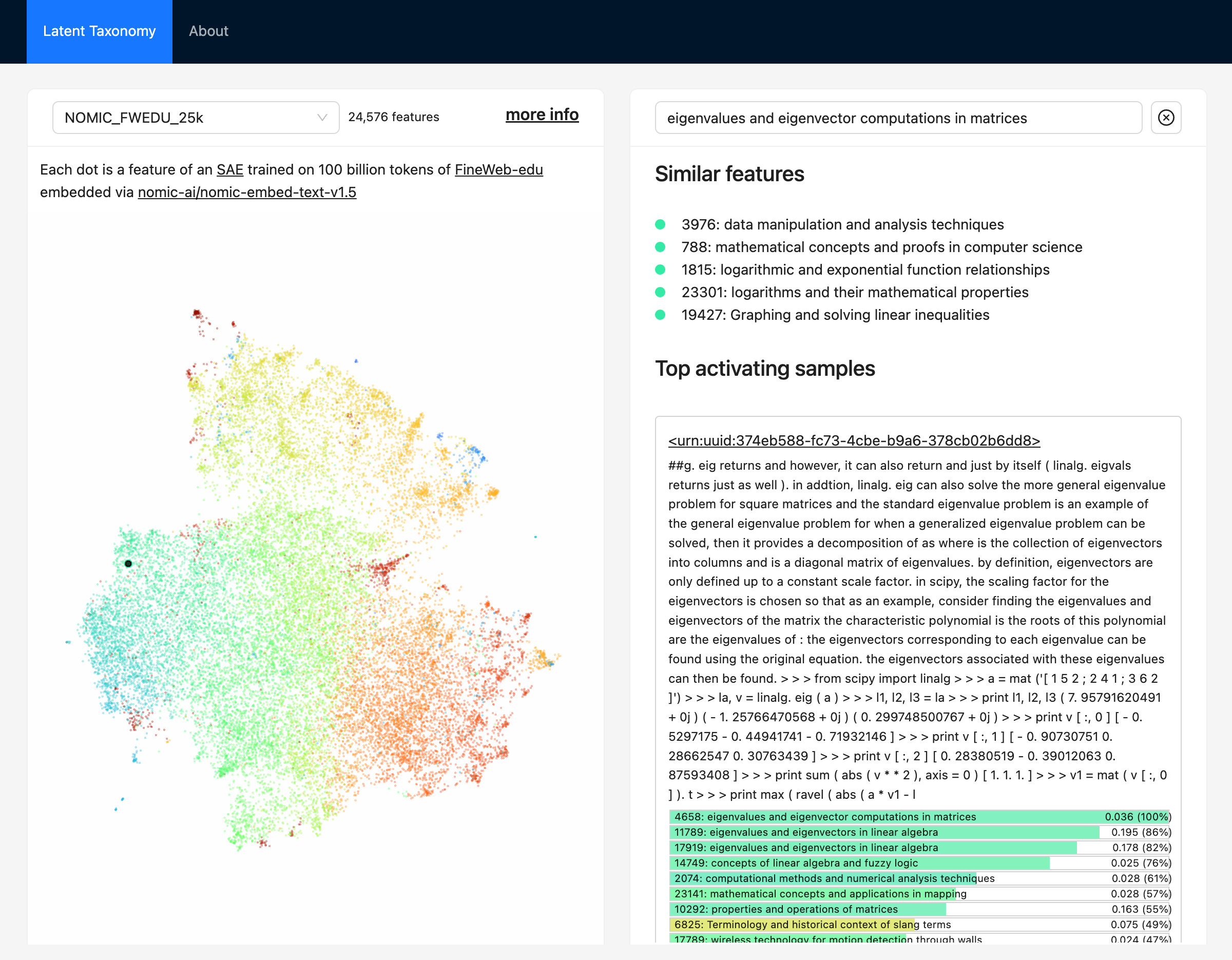
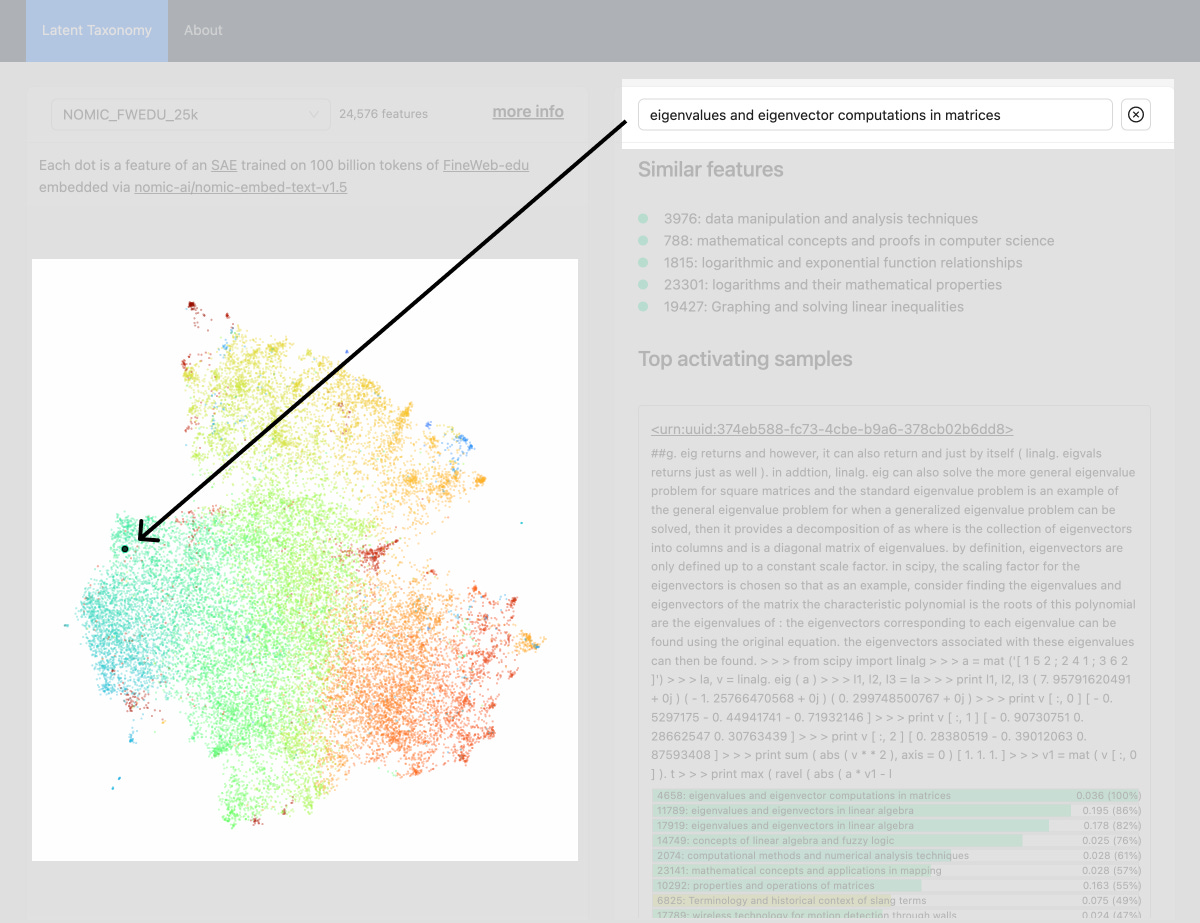
Interactive taxonomy of an SAE model, for reference and downstream uses of the SAE. This work is being done in the latent-taxonomy repo. You can play with the 25k features currently supported in this interactive webapp.
Extract SAE features of a dataset directly in Latent Scope, this work is being tracked in this issue in the latent-scope repo.
It will be exciting to be able to filter your datasets by a specific feature, like stress related to buttons, plant identification strategies, or cybersecurity vulnerability detection. The breadth of concepts captured by the SAE from embeddings is impressive, and this is just the small version! I'll likely do another newsletter soon about all of the things I'm experimenting with around SAEs as the technical and design challenges are numerous.
Join the discussion on the Latent Interfaces discord or just reply to this email if you want to chat about anything related to embeddings UX!