
Insights with Embeddings
Latent Scope 0.2

Latent Scope is ready to be battle tested with production data! I'm looking for a client to partner with and develop custom data curation workflows for large unstructured text datasets. If you or someone you know has an overwhelming amount of text they need to extract value from please get in touch.
We're all generating and collecting enormous amounts of data, yet much of it remains unexamined because looking at it is unfeasible with traditional data analysis techniques. Recent advancement in LLMs, particularly in embedding models, have unlocked a new way to pull understanding from unstructured data. Putting these new capabilities into practice is fraught with operational challenges and the constantly evolving model landscape. That's why I've been building Latent Scope, an open source tool that streamlines the process of getting insights from unstructured data.
To demonstrate this process I've published an example analysis of 50,000 U.S. Federal Laws since 1789. One insight that immediately jumped out is that there are neat clusters of ~3,000 laws about building bridges, ~2,500 laws concerning Native Americans but surprisingly there are no obvious clusters of laws about Civil Rights.

In this way, Latent Scope can act as a kind of observability for embedding applications. Without being able to visualize the clusters and the search results it would be very difficult to know how well represented (or not represented) various concepts are in my dataset.
Combining structured and unstructured data
I put together an example analysis of my 10,000 tweets over 16 years on Twitter to highlight the potential for augmenting existing data with the meaning extracted from unstructured text. While it may not be a surprise to anyone who's been following this newsletter a long time, my most liked tweets revolve around D3.js and data visualization. The area of the map that has the most overlap between tweets, retweets and replies are all clusters related to D3!

By combining the structured data with the extracted categorizations we can do things like see which topics got the most likes and retweets. It's usually very difficult to act on metrics alone, there is always some context missing, now it's possible to get the context systematically!
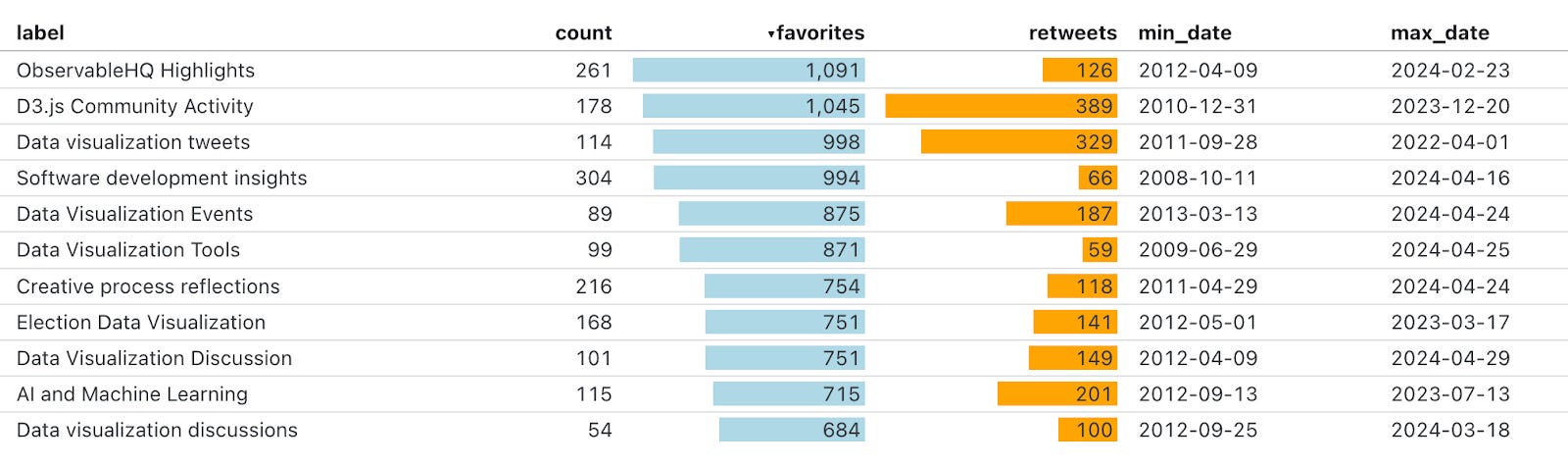
You can run latent scope on any decent computer, many of the open source embedding models can process thousands of rows per minute with just a CPU. It only took me 5 minutes to run my 10,000 tweets through the entire process end-to-end on my M2 mac.
Latent Scope is now on version 0.2, with a simpler setup process and a more robust and unified interface for filtering and curating data. The export format has been iterated on to make it easier to incorporate in other analysis tools. There is now more thorough documentation with a guide to your first scope and how to use the explore & curate page.
Why does Latent Scope exist?
I've developed Latent Scope to systematically do what I've done in an ad-hoc way at my previous jobs. I'm excited about this process but I'm tired of reinventing the wheel!
I've been doing data engineering & visualization professionally for the past 20 years and the mandate is always the same: impose structure on data to highlight patterns and extract insights. The discipline is well developed and I've always enjoyed the challenge of encoding data into visualizations, but then in 2016 I felt the ground shift when I learned about the concept of latent space.
I was introduced to t-SNE by building the interactive visualizations for the popular Distill article about the algorithm. Getting a feel for the power and flexibility of t-SNE, and soon after, UMAP primed me for the revelation of embeddings. Before t-SNE I had to manually figure out which features of a dataset were interesting enough to show, but with this new tool I was able to automatically organize data in interesting ways.
Then the Distill researchers patiently taught me about latent space, we explored embedding visualizations of a Handwriting model and then visualized neural network activations in The Building Blocks of Interpretability and Activation Atlas. The very thing that made neural networks so effective was captured in their hidden layers and it turned out that if you could look at what was in those layers you could get insight into what the machine had learned.
During that time I was helping curate training data for SketchRNN and then contribute to open sourcing the QuickDraw dataset. When I applied t-SNE to the SketchRNN embeddings of the drawings I became fully convinced of the power of Machine Learning for Data Visualization.

Here was a dataset that defied traditional data visualization techniques, sure you could organize it by what country it was drawn in, or how many strokes were in each drawing, but to get at the actual meaning of the drawing was out of reach for traditional tools. With embedding visualization it was possible to organize the data by its actual content, finding clusters of subjectively good drawings. We also got an insight into the unexpected ways people were playing the QuickDraw game!

In 2018 I began applying this idea of visualizing embeddings with some colleagues on Google Cloud. We built out a suite of tools for making sense of usage patterns for hundreds of Google Cloud products, finding patterns in user behavior and building out data-driven personas. While I can't share too many details we did find surprising insights into how our users were combining product offerings in ways our product teams had not foreseen.

It was exciting to see a valuable business application of the concept, but at the time it took quite a lot of resources to execute on the backend and I wanted to focus on building data interfaces.
So in 2020 I took a small detour from embeddings and joined Observable to help make advanced data visualization more accessible to teams. There I continued to curate data and refine my visualization practice until the end of 2022 when I felt it was time to strike out on my own.
I got back to embeddings with some work for Stability.ai, helping curate training data for iterations of Stable Diffusion. Re-implementing the process on a new infrastructure reinforced the concepts but highlighted the drag of having to reinvent the wheel. It was also exciting to see the rapid developments of open source models like CLIP and StableDiffusion with capabilities blowing past the VAEs, RNNs and CNNs I had been working with in 2017. While I was focused on curating good data to improve models, I stumbled upon a dramatic insight. Perusing the clusters of user generated images, certain disturbing images showed up. Because of this we were able to rapidly identify, classify and put a stop to an influx of harmful image generations.

What's Next?
The next step for Latent Scope is to take this process into a production environment where data is being underutilized because its value isn't accessible. I'm especially interested in datasets that grow over time. Some use-cases I can imagine are:
Curating training data for fine-tuning domain-specific models
We all know the adage: "garbage in, garbage out", but how do you know what's in a multi-million or multi-billion token dataset? I'd like to use Latent Scope to generate detailed reports on dataset composition and quality. The outcome would be actionable ways to augment the training data.
Curating knowledge bases for RAG applications
Similar to curating training data, knowing the composition of your dataset will greatly impact the quality of your RAG responses. If certain concepts or documents are underrepresented, the LLM won't have the context it needs to answer queries. We should be able to systematically determine the document distribution and create an actionable report for addressing deficiencies.
Insight discovery in low signal-to-noise datasets
Data may be the new oil but a lot of it is very crude. That doesn't mean we can't process it to find the good stuff. I'd like to use Latent Scope to sift large unstructured datasets to extract meaningful data. I'm especially interested in training classifiers based on what we find to filter production data as it comes in.
In my experience being able to see what's in the data that's fed into production processes will always generate surprising insights, then after the surprise wears off you gain a new sense of confidence in the process.
I also know that in real-world workflows a tool like Latent Scope is going to be a part of a larger process and integrating it will take some customization and adapting. My hope is to find a client that I can work closely with to add value to their data and make Latent Scope more robust in the process.
If that sounds like you or anyone you know, please get in touch!